You are here: Product Overview > Product Overview > About VoiceXML and Voice Browsers
About VoiceXML and Voice Browsers

VoiceXML, or Voice eXtensible Markup Language, is a dialog markup language that leverages the other specifications for creating dialogs that feature synthesized speech, digitized audio, recognition of spoken and DTMF key (touch tone) input, recording of spoken input, telephony, and mixed initiative conversations.
Associated specifications such as the Speech Synthesis Markup Language (SSML), Speech Recognition Grammar Specification (SRGS), and Call Control XML (CCXML) are core technologies for describing speech synthesis (text-to-speech), recognition grammars (automatic speech recognition), and call control constructs respectively.
VoiceXML is the HTML of the voice web, the open standard markup language for voice applications. Where HTML assumes a graphical web browser with display, keyboard, and mouse, VoiceXML assumes a voice browser with audio output (recorded messages and TTS synthesis), audio input (ASR), and keypad input (DTMF).
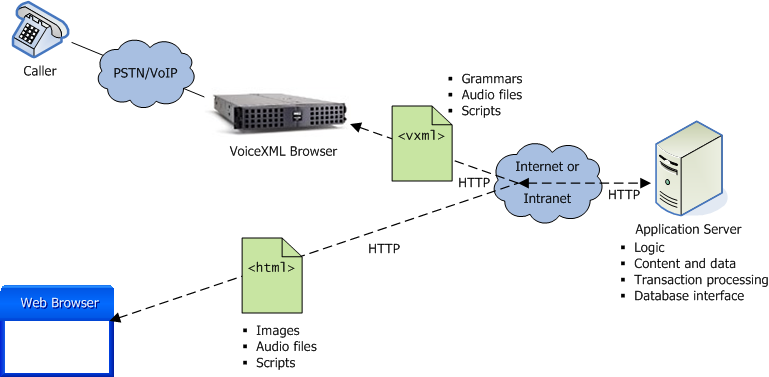
The following illustration compares telephone and web application architectures.
A basic element of VoiceXML is a XML document, either a static file or a dynamically generated one. VoiceXML is designed for creating interactive audio dialogs.
VoiceXML documents describe:
u Output of synthesized speech (text-to-speech)
u Output of audio files
u Recognition of spoken words and phrases
u Recognition of DTMF key input
u Recording of spoken input
u Mixed-initiative conversations
u Control of dialog flow
u Control of call processing (call transfer, disconnect)
VoiceXML documents are processed by a VoiceXML interpreter, complying with VoiceXML specifications by W3C. In general, a VoiceXML interpreter:
u Fetches documents from a Web (application) server by means of the HTTP standard protocol
u Builds dialogs
u Calls the appropriate resources to:
n Interpret input (ASR or DTMF)
n Generate output (TTS or pre-recorded audio)
Note: A VoiceXML Interpreter is not the same as a voice browser – it is one part of the voice browser.
A voice browser is a collection of software that works together to integrate and manage telephony, automatic speech recognition (ASR), text-to-speech (TTS), DTMF (touchtone), third party or custom services, media, and other resources required to run VoiceXML applications.
The Vocalocity Voice Browser is a packaged solution that manages telephony, automatic speech recognition (ASR), text-to-speech (TTS), DTMF, third party or custom services, media, and other needed resources. This integrated product allows developers to create VoiceXML applications, and integrate with multiple ASR and TTS servers. For more information about the Vocalocity Voice Browser, see the section, Features of CSP VoiceXML Release 1.1.
Vocalocity is a member of the W3C Voice Browser Working Group. The Working Group has defined a suite of markup languages covering dialog, speech synthesis, speech recognition, call control and other aspects of interactive voice response applications.
Vocalocity is one of the W3C Editors of VoiceXML 2.0, VoiceXML 2.1, CCXML 1.0 and SSML. Additionally, Vocalocity is a Board Member of the VoiceXML Forum and its Chief Architect serves as the organization's Vice Chair. For more information about the:
u W3C Voice Browser Working Group, go to www.w3c.org/Voice
u VoiceXML Forum, go to www.voicexml.org
A typical call goes through these steps:
1 A user calls a telephone number using a normal telephone (or a mobile phone).
2 The call is routed via PSTN (Public Switching Telephone Network) or IP to the voice browser, which activates a VoiceXML interpreter.
3 The voice browser contains the mapping logic – in Vocalocity software, this is called call routing – between the called telephone number and a URI (uniform resource indicator), which points to a specific VoiceXML document.
4 The VoiceXML document is loaded, interpreted, and processed by the VoiceXML interpreter.
5 The speech output, processed by the TTS system, is sent to the caller and speech input recognition processed by the ASR or DTMF component.